Künstliche Intelligenz gilt als Schlüsseltechnologie der Industrie. Doch den meisten Unternehmen fehlt Know-how, um passende Lösungen bedienen zu können und ihren Ergebnissen zu vertrauen. Ein KI-Framework, das mit einer zusätzlichen, kennzahlenbasierten Interpretationsebene arbeitet und zwischen drei Anwendergruppen unterscheidet, löst diese Crux und bietet Betrieben in Abhängigkeit ihrer KI-Vorkenntnisse den jeweils passenden Einstieg.
Der Einsatz künstlicher Intelligenz (KI) für Prognosen und Prognoseentscheidungen birgt enorme Effizienz- und Produktivitätspotenziale, etwa in der Wartung und Instandhaltung von großen Anlagenverbünden oder in der Verwaltung und Visualisierung von verketteten Arbeitsabläufen in der Produktion. Weil dabei wettbewerbsentscheidende Vorteile entstehen, nimmt der Handlungsdruck auf Unternehmen kontinuierlich zu. Gleichzeitig kann von einer flächendeckenden Nutzung von KI-Anwendungen in der Industrie noch lange nicht die Rede sein. Ihr steht u.a. im Weg, dass entsprechende Lösungen ausschließlich Datenanalysten verstehen, anpassen und steuern können. Doch nur wenige Unternehmen beschäftigen Datenwissenschaftler oder finden passende Nachwuchstalente. Blind wollen viele Verantwortliche den Prognosen oder automatisierten Entscheidungen einer vermeintlichen Blackbox aber nicht vertrauen und zögern daher mit der Integration entsprechender Anwendungen. Da der selbstständige Aufbau von KI-Wissen wiederum viel Zeit in Anspruch nimmt bzw. für viele Betriebe gar nicht zu stemmen ist, werden KI-Lösungen gebraucht, die auch ohne Spezialwissen nachvollziehbar und intuitiv bedienbar sind und als solche dem Wissensstand unterschiedlicher Anwendergruppen Rechnung tragen.
Kennzahlen-basierte Interpretationsebene
Ein etablierter Softwarehersteller löst dieses Manko über eine zusätzliche, kennzahlenbasierte (KPI) Interpretationsebene mit seinem KI-Framework. Diese KPI-Interpretationsebene ermöglicht es auch Anwendern, die über Prozess-Know-how verfügen, aber keine Datenanalysten sind, mit dem Framework erstellte KI-Systeme zu verstehen und zu bedienen. So können Unternehmen mit einem vorkonfigurierten System starten und müssen neben der Bereitstellung von relevanten Daten lediglich festlegen, nach welchen Kennzahlen und Kriterien (KPIs) die Qualität der Ergebnisse bewertet und gegebenenfalls optimiert werden soll.
Kern dieses Systems ist ein maschinelles Lern- und Entscheidungsverfahren, das auf der automatischen Erkennung von Zielkonflikten zwischen Kennzahlen beruht – und zwar sowohl in Eingabedaten als auch auf Daten, die durch maschinelles Lernen entstanden sind. Dabei kann das KI-Framework Daten aller Prozessebenen verarbeiten. Auf Basis der Zielkonfliktanalyse der Entscheidungsmaschine ordnet und labelt das System die Daten automatisch derart, dass ein generischer Prognose-Algorithmus selbstständig erkennen kann, in welchen Situationen wie vorzugehen ist. Das Ziel: die bestmögliche und konsistente Entsprechung der Entscheidungen und Prognosen mit den ermittelten Datenmustern. Die Daten werden wiederum systematisch in sogenannten Wirkungs- und Beziehungsmatrizen übersetzt und visualisiert – und zwar aus der Perspektive der jeweiligen (Prozess-)Datenpunkte und damit aus einer neuen Perspektive für die Erklärbarkeit von KI-Analysen und -Ergebnissen.
Drei Anwendergruppen
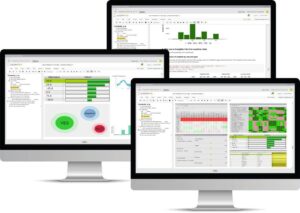
Prinzipieller Aufbau der GUI-Elemente und Bestandteile der korrespondierenden Anwenderrollen
Die Prognoseergebnisse entsprechen prinzipiell denen gängiger Verfahren. Der Vorteil liegt jedoch in der hohen Praxistauglichkeit des Systems: Neben seiner Branchen- und Plattformunabhängigkeit sowie der freien Kombinierbarkeit mit unterschiedlichsten KI-Standardanwendungen unterscheidet das Framework drei Anwendergruppen mit unterschiedlichen Vorkenntnissen und stellt jeweils geeignete Elemente in der Bedienoberfläche zur Verfügung.
– Operators: Anwender dieser Zielgruppe verfügen über Prozesswissen und agieren wie Systembetreiber. Das heißt, sie arbeiten mit einem vorkonfigurierten System und erhalten KPI-orientiert, verständlich aufbereitete Handlungsempfehlungen. Die Ergebnisse nehmen sie in Geschäftsprozesse auf und nutzen sie dort weiter. Zudem können sie die Empfehlungen bestätigen, verneinen oder via Präferenzeinstellungen anpassen. Auf Basis der Rückmeldungen erfolgt ein rollierendes Training des Systems, d.h., die KI-Anwendung kann sich selbstlernend verbessern.
– Key-User: Die Gruppe der Key-User konfiguriert und parametriert die KI-Anwendung zusätzlich aktiv auf der Ebene der Prozesskennzahlen. Hierfür stehen den Anwendern die Erklärungsmechanismen der KPI-Wirkungsanalysen sowie Visualisierungen der KPI-Beziehungen zur Verfügung, aus denen das System automatisch Präferenzrelationen ableitet und erlernt. Auf dieser Basis können Key-User die Anwendungen über einfache Bedienelemente modellieren sowie die Sensitivität der Verfahren anpassen, ohne auf Code-Ebene als Programmierer zu arbeiten.
– Datenanalysten: Die dritte Gruppe richtet sich an Datenanalysten mit ausgeprägten KI-Programmier-Kenntnissen. Sie erhalten im Framework den Zugriff auf alle Funktionalitäten der Entscheidungsmaschine sowie einen vollen KI-Stack, der die Kombination verschiedener Methoden der künstlichen Intelligenz je nach Geschäftsprozess bereitstellt. Diese Anwender können zudem auf alle Nutzerrollen zurückgreifen und eigenständig Anwendungen umsetzen. Hierbei unterstützen die Erklärungsmechanismen erneut entscheidend, da sie auch für Spezialisten den Einblick in die Art und Weise des Zustandekommens der Ergebnisse vereinfachen.
Leichter Einstieg in KI-Anwendungen
KI-Lösungen werden nur dann mit dem erforderlichen Tempo erfolgreich in der Industrie ankommen, wenn sie unterschiedlichen Vorkenntnissen ihrer Anwender Rechnung tragen und sich nicht nur an Datenanalysten richten. Das schafft ein KI-Framework, das zusätzlich über eine kennzahlen-basierte Interpretationsebene verfügt und zwischen drei zentralen Anwendergruppen unterscheidet. Diese Herangehensweise ermöglicht Unternehmen die Nutzung unterschiedlichster KI-Anwendungen – und zwar sowohl Datenanalysten als auch Anwendern mit Prozess-Know-how.
![]()
Textquelle: PSI FLS Fuzzy Logik & Neuro Systeme
Bildquelle: Aufmacher stock.adobe.com – greenbutterfly; weiteres Bild PSI FLS